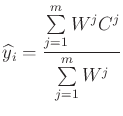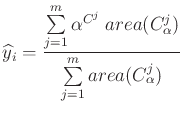Next: The Performance Function Up: C++ Function Library Previous: C++ Function Library Contents
The FIS handled by the function library are MIMO type FIS, Multiple Input Multiple Output. The FIS is built by using the information of the configuration file. The basic module contains two main functions, defined within the FIS class: Infer and Performance.
The Infer function infers a value for each active output from the input values. Fuzzy inference obeys the following steps:
IF Input 1 is MF 2 AND Input 2 is MF 1 THEN Output 1 is Value 1
(crisp output)
IF Input 1 is MF 1 AND Input 2 is MF 1 THEN Output 1 is MF 2
(fuzzy output)
The ExecRule function of the RULE class calculates the matching degree of the item to the rule, also called rule weight. The calculation is done within the PREMISE class. It uses a conjunction operator between the fuzzy sets in the rule premises for the input variables (Input 1 and Input 2). These fuzzy sets are described by the number 2 and number 1 membership functions for the first rule, 1 and 1 membership functions for the second one). The PREMISE class includes a pointer on the input variable array, which gives it access to the Mfdeg field for each input. The rule matching degree is stored in the public variable Weight within the RULE class. When expert weigts are set (see section FIS menu- Rule window), the rule matching degree is multiplied by the expert weight.
The rule conclusions are numerical values for a crisp output, or MF labels for a fuzzy output. They constitute a set of possible values.
The resulting levels are stored into the MuInfer array, the RuleInfer one contains the number of the rule corresponding to the maximum, in case of max aggregation, or the last rule number whose degree has been added, in the sum aggregation case. Both operators can be used with crisp or fuzzy output.
Note :
![]() the number of fuzzy rules,
the number of fuzzy rules, ![]() the
the ![]() rule matching degree for the multidimensional vector
rule matching degree for the multidimensional vector ![]() .
.
![]() the number of output MFs (fuzzy output) or the number of distinct rule conclusion values (crisp output).
the number of output MFs (fuzzy output) or the number of distinct rule conclusion values (crisp output).
![]() the conclusion of the
the conclusion of the ![]() rule.
rule.
The activation levels after aggregation are the following:
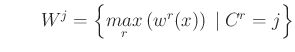
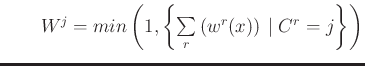
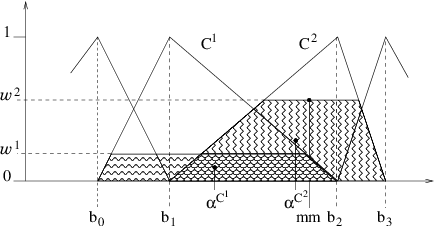
Figure 5 illustrates the defuzzification possibilities for a fuzzy output.
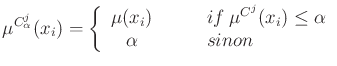
Implication operators
For implicative outputs, three implication operators are available :
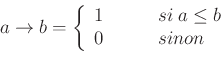
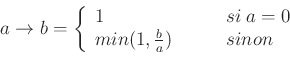
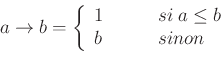
The inference result is a possibility distribution, which may be defuzzified. In the current implementation, no choice is available for the defuzzification operator. The default one is the Mean of maxima, which corresponds to the middle of the distribution kernel.