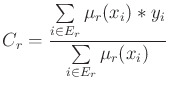suivant: Menu Données monter: Menu Sif précédent: Générer règles Table des matières
Les conclusions des règles peuvent être calculées par la méthode des moindres carrés, pour minimiser la somme des carrés des erreurs entre les sorties observées et celles inférées par le modèle, ou bien générées par un algorithme inspiré de Fpa, qui est l'acronyme en anglais d'algorithme de prototypage rapide [6,7]. Quelle que soit l'option choisie, il est ensuite possible de réduire le vocabulaire de sortie.
Fpa
La méthode Fpa consiste en un algorithme simple qui permet d'initialiser ou d'actualiser la conclusion des règles à partir d'un jeu de données d'apprentissage.
L'initialisation des conclusions se fait à partir des valeurs observées pour un ensemble d'exemples choisis, dont le choix est expliqué plus loin, ![]() pour la règle r. Considérons d'abord le cas d'une sortie nette.
pour la règle r. Considérons d'abord le cas d'une sortie nette.
Si l'on travaille en classification, la conclusion de la règle est simplement la classe majoritaire dans ![]() .
.
Dans le cas d'une sortie continue, l'initialisation la plus simple consiste à calculer la conclusion comme la somme, pondérée par les degrés de vérité, des sorties observées dans ![]() . Soit, en notant
. Soit, en notant
![]() le degré de vérité de l'exemple i pour la règle r, et
le degré de vérité de l'exemple i pour la règle r, et ![]() la sortie observée de l'exemple i :
la sortie observée de l'exemple i :
L'initialisation d'une conclusion floue se fait en deux temps. Tout d'abord une sortie nette est calculée suivant l'équation 1, comme pour une sortie continue. Puis, la conclusion de la règle est choisie comme le numéro de l'ensemble flou pour lequel le degré d'appartenance de la sortie nette est maximum.
Revenons sur le choix de l'ensemble ![]() .
Il est formé d'exemples choisis en fonction de leur degré de vérité pour la règle, suivant deux stratégies possibles.
Il est formé d'exemples choisis en fonction de leur degré de vérité pour la règle.
.
Il est formé d'exemples choisis en fonction de leur degré de vérité pour la règle, suivant deux stratégies possibles.
Il est formé d'exemples choisis en fonction de leur degré de vérité pour la règle.
La première stratégie, dite décrémentale, consiste à ne retenir que les exemples qui activent le plus la règle. Leur nombre minimum est fixé par le paramètre EffectifMin. Le degré de vérité seuil est d'abord fixé à un maximum (0.7, donné par la constante START_DEC). Si le nombre d'exemples, dont le degré de vérité pour la règle est supérieur ou égal au seuil, est inférieur à EffectifMin, la valeur seuil du degré de vérité est décrémentée par pas. La valeur du pas est fixée par la constante STEP_DEC, qui vaut actuellement 0.1. La procédure décrémentale s'arrête dès que le nombre d'exemples est suffisant, ou bien si le degré seuil atteint une valeur limite paramétrée, MuMin.
Cette stratégie privilégie les exemples proches des prototypes de la règle, dont la définition est donnée dans le glossaire de la section V.
La seconde, dite minimum, consiste à considérer l'ensemble des exemples dont le degré de vérité pour la règle est supérieur à un seuil donné, MuMin. Cette stratégie, par l'utilisation d'un ensemble plus large, autorise l'emploi de procédures plus fines, telles qu'une descente de gradient. Dans ce cas, la valeur initiale peut être également déterminée suivant l'équation 1. La stratégie appliquée consiste à considérer l'ensemble des exemples dont le degré de vérité pour la règle est supérieur à un seuil donné, seuil blanc.
Quelle que soit la stratégie appliquée, si le cardinal de ![]() est inférieur à EffectifMin, la règle correspondante n'est pas sélectionnée car son influence dans l'ensemble d'apprentissage est jugée insuffisante.
est inférieur à EffectifMin, la règle correspondante n'est pas sélectionnée car son influence dans l'ensemble d'apprentissage est jugée insuffisante.
Le rôle des paramètres EffectifMin et MuMin est différent dans chacune des stratégies. La stratégie décrémentale est pilotée par le paramètre d'effectif, le degré de vérité minimum constituant une limite, tandis que la stratégie minimum est pilotée par le paramètre de degré de vérité, l'effectif minimum n'étant qu'une vérification.
OLS (Minimisation par les moindres carrés
L'algorithme optimise les conclusions des règles en minimisant la somme des carrés des erreurs (voir 3.2.3).
Réduction du vocabulaire de sortie
Cette option permet de réduire le nombre de conclusions distinctes des règles dans un SIF, et ainsi d'améliorer la lisibilité de la base de règles. Dans le cas d'une sortie nette de type régression, les valeurs des conclusions des règles sont distinctes les unes des autres: a priori il y en a autant que de règles a l'issue d'une procédure d'apprentissage.
Il faut indiquer à partir de quelles valeurs la réduction doit s'opérer. Deux choix sont possibles : soit les conclusions des règles existantes, soit les valeurs de la variable de sortie dans le fichier de données. La réduction consiste en une opération de clustering des conclusions ou des valeurs de sortie pour obtenir les valeurs finales des conclusions.
L'utilisateur peut fixer le nombre de valeurs désiré ou bien spécifier une perte de performance tolérée. En effet, la réduction de vocabulaire s'accompagne en général d'une perte de précision.
Lorsque le vocabulaire a été réduit, il est possible de “fuzzifier” la sortie, c'est à dire construire une partition floue forte à partir de ces valeurs en nombre réduit. Il suffit pour cela de transformer la sortie nette en sortie floue dans la fenêtre Sortie.