suivant: Liens monter: Menu Données précédent: Table Table des matières
Le résultat de l'inférence, lorsqu'elle est effectuée à partir d'un
fichier de données, est stocké dans un fichier texte qui peut être lu
par un tableur. Le format de ce fichier, en particulier son nombre de
colonnes, dépend du type d'opérateur de défuzzification choisi pour la
sortie étudiée. Il est décrit en détail dans la section 2
de la partie II de ce document.
Dans la fenêtre, il faut choisir la sortie sur laquelle on fait
l'inférence. Si la sortie est présente dans le fichier de données, l'erreur est caractérisée par le nombre d'exemples mal classés dans le cas d'une sortie de type classification, et dans le cas d'une sortie continue par trois indices de performance, PI, RMSE et MAE définis dans la section (voir section V du glossaire).
Un fichier résumé des performances est disponible, voir la section 2 pour son format.
Remarque : les procédures d'apprentissage sont toutes caractérisées par le RMSE.
Les fonctions d'affichage présentées dans la visualisation des données sont disponibles pour visualiser les résultats : histogrammes, graphes X-Y avec ou sans droite de régression. Dans le graphe X-Y, si l'option Liens entre règles et données a été choisie dans la fenêtre Inférer, des informations peuvent être obtenues sur chaque point en faisant glisser la souris sur le point : numéro de ligne de l'exemple dans le fichier de données, et numéros des règles activées (au-delà du seuil blanc choisi).
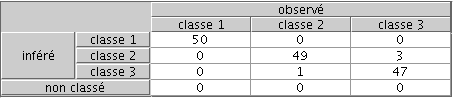
Pour la classification, le résultat n'est pas un graphe X-Y, mais une matrice dite de confusion. L'exemple de la figure 1 montre que les 50 exemples de la classe 1 sont bien classés par le système, 49 exemples de la classe 2 sont bien classés et 1 mal classé (classe inférée=classe 3), et 47 exemples de la classe 3 sont bien classés et 3 mal classés (classe inférée=classe 2).
Remarque : la classification correspond à une sortie nette, avec l'option classification cochée.
Sorties implicatives
Pour les sorties implicatives, le graphe X-Y présente la valeur inférée sous forme d'intervalle dont les bornes correspondent au minimum et maximum du noyau de la distribution de possibilité inférée.
Une option supplémentaire est disponible pour les sorties implicatives, elle permet de calculer, pour chaque exemple, le degré d'adéquation de la sortie inférée avec la sortie calculée. Cette option est inspirée de la matrice de confusion en classification, mais elle tient compte du fait que la sortie inférée est une distribution de possibilité, et non pas une valeur unique obtenue par défuzzification, comme c'est le cas dans les règles conjonctives.
Le degré d'adéquation varie entre 0 et 1. Il est calculé à partir de l'intersection de la distribution de possibilité inférée avec les SEF de sortie, et tient compte de l'amplitude de cette distribution. Le résultat est cumulé et affiché sous forme de tableau, avec une ligne par SEF de sortie, une colonne degré d'adéquation et une colonne exemple.
Attention : quel que soit le type de système, implicatif ou
conjonctif, l'indice de performance ne prend en compte que les exemples qui activent les règles au-delà du seuil blanc choisi (![]() par défaut).
par défaut).