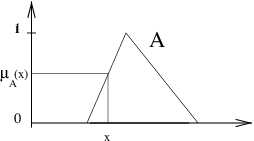
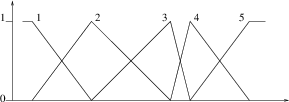
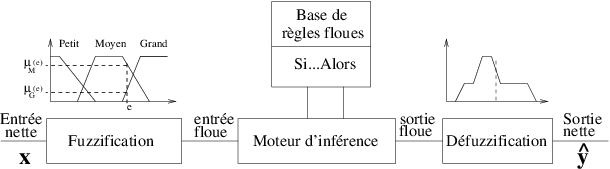
Les règles, de la forme Si x est A alors y est C sont de deux types :
- Règles conjonctives : Dans ce cas la règle représente une connaissance positive, les entrées (A) et sortie (C) sont des paires de valeurs conjointement possibles. La sémantique de la règle est : Si l'entrée est de type A alors une valeur possible pour la sortie est C. La relation entre l'entrée et la sortie de la règle est modélisée par une conjonction (t-norme). Ces règles s'inspirent de la philosophie des bases de données, c'est possible car je l'ai observé, et implémentent le raisonnement par similarité. La sortie est une distribution de possibilité garantie.
- Règles implicatives : La règle représente une connaissance négative, et la sémantique devient “Si l'entrée est de type A alors la sortie est obligatoirement dans C”. Cette deuxième forme d'expression, plus formelle, est issue de la branche logique et intelligence artificielle de l'informatique. Au lieu de procéder par accumulation, elle procède par élimination : sont écartées les valeurs qui ne respectent pas les contraintes. La relation entre l'entrée et la sortie de la règle est modélisée par une implication, éventuellement floue. La sortie est une distribution de possibilité potentielle (usuelle). Le passage, pour un expert, de la connaissance positive à la connaissance négative suppose une étape de modélisation.
Pour une comparaison plus approfondie entre les deux types de règles, se reporter à [12].
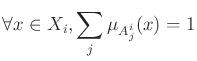 .
.