suivant: Génération des règles monter: Partitions précédent: Générer un SIF sans Table des matières
Nous présentons simplement ici différentes options proposées dans le menu. Seul un fichier de données doit être ouvert. Si un SIF est ouvert, le programme n'en tient pas compte. La sortie est la dernière colonne du fichier de données.
Pour utiliser cette méthode, les opérations sont à faire dans un certain ordre, car elles créent des fichiers intermédiaires :
| Générer un fichier de configuration pour HFP |
| Générer les sommets |
| Sélectionner une partition |
| Examiner le fichier créé par l'étape précédente (result.min), |
| pour déterminer le meilleur nombre de SEF pour chaque entrée |
| Générer un SIF (Apprentissage-Induction de règles-HFP SIF) |
Les options sont détaillées ci-dessous :
Pour chaque variable (colonne du fichier de données), l'utilisateur peut modifier la taille maximum de la partition (valeur par défaut=7). La dernière colonne est par défaut laissée de côté (considérée comme une sortie) pour la construction des partitions. La conjonction des prémisses est paramétrable.
Le paramètre le plus important de cette étape est le type de hiérarchie à générer. 3 choix sont possibles :
La seconde option proposée est d'utiliser une méthode de groupage éprouvée, les k-means. Il n'y a, a priori, aucune relation entre les centres des différentes partitions d'une même entrée.
Cette dernière possibilité est une procédure ascendante. A chaque étape, au sein d'une entrée, deux sous-ensembles flous sont fusionnés. Le temps de calcul peut être important. Il dépend principalement, du nombre de sous-ensembles flous dans la partition initiale. Celle-ci peut être constituée de deux manières. La première consiste à regrouper les valeurs de l'ensemble d'apprentissage en considérant que deux d'entre elles sont identiques si leur différence est plus petite que le seuil fixé, en pourcentage du domaine de variation. Le nombre de groupes retenu, chacun correspondant à un sous-ensemble flou, dépend directement de ce seuil. La seconde possibilité, est de fixer le nombre de groupes dont les centres seront calculés par les k-means.
Cette option crée un fichier qui comprend l'ensemble des coordonnées des centres pour toutes les partitions, de deux au nombre maximal fixé de sous-ensembles flous (7 par défaut), et ce, pour chacune des variables choisies lors de l'étape précédente, conformément au fichier généré lors de l'étape précédente.
Cette option permet de visualiser la position des sommets, en regard de l'histogramme des données. Sous chacune des partitions sont affichés deux indices : le coefficient de partition, ![]() , à maximiser, et le coefficient d'entropie,
, à maximiser, et le coefficient d'entropie, ![]() , à minimiser.
, à minimiser.
Dans les formules suivantes, ![]() est le nombre de SEF,
est le nombre de SEF, ![]() le nombre d'exemples du jeu de données et
le nombre d'exemples du jeu de données et ![]() le degré d'appartenance de l'exemple
le degré d'appartenance de l'exemple ![]() au SEF
au SEF ![]() .
.
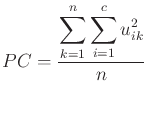
![$\displaystyle PE = - \frac1n \left\{\sum_{k=1}^n \sum_{i=1}^c \left[u_{ik} \log_a (u_{ik})\right]\right\}.$](img15.png)
Les hiérarchies mono dimensionnelles calculées à l'étape précédente sont utilisées pour construire des systèmes d'inférence floue qui sont à la fois compacts et performants.
Parmi les paramètres figure le nombre initial de sous-ensembles flous, 1 ou 2. Choisir 1, revient, de fait, à introduire progressivement les variables dans le système. Pour chacune des combinaisons, c'est-à-dire un nombre de SEF par entrée, le système, formé de l'ensemble des règles possibles, est caractérisé par des indicateurs de performance et de couverture. A chaque itération, un nouveau SEF est ajouté sur une et une seule entrée suivant le critère d'amélioration de le performance.
L'autre paramètre important est celui de la méthode d'induction de règles. Deux sont disponibles : l'algorithme de Wang et Mendel (pas de paramètres supplémentaires) et la méthode FPA. Dans ce cas, les autres paramètres sont ceux de Générer conclusions (voir section 1.8) pour initialiser la conclusion des règles. Enfin, il faut spécifier le nombre maximum d'itérations et le nom du fichier sommets à utiliser.
La performance peut être calculée sur un fichier de validation différent du fichier de données (qui a servi pour initialiser la conclusion des règles) : données actives ou inactives gérées par l'option table du menu Données, ou autre fichier.
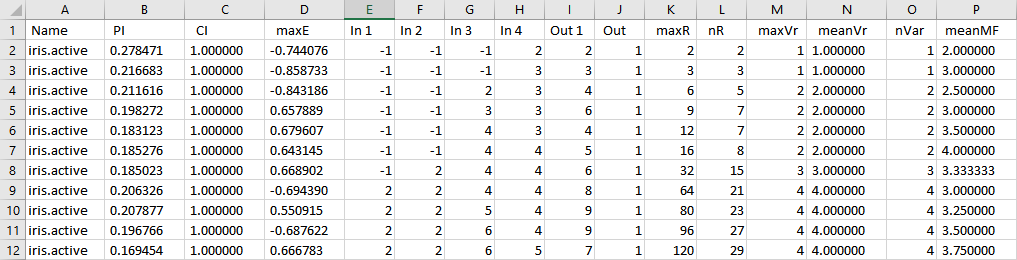
Le résultat de chaque itération est stocké, sous la forme d'une ligne dans les fichiers "result" et "result.min". Le fichier "result" contient l'ensemble des tentatives (ajout d'un sef sur chacune des variables d'entrée), le fichier "result.min" indique la configuration retenue après chacune des itérations.
Format : les colonnes sont séparées par le délimiteur &, qui permet de relire le fichier dans un tableur, ou d'introduire directement le tableau dans un document LATEX.
Les indices de performance et de couverture sont décrits dans la section 2, les caractéristiques de la base de règles dans la section 3 de la partie II de ce document.
L'analyse de ce fichier permet de choisir le ou les SIF que l'on souhaite générer. Les éléments à prendre en compte sont la performance (colonne 6) associée au niveau de couverture (colonne 4), mais aussi la complexité de chacun des systèmes mesurée par le nombre de règles et les caractéristiques de la base de règles données par la structure InfoRB (voir partie II, section 3) .
La performance, qui est une mesure d'erreur doit être la plus petite possible (minimum 0) avec un indice de couverture le plus grand possible (maximum ![]() ) tandis que le nombre de règles ainsi que le nombre de SEF doivent être raisonnablement petits. Le compromis entre la complexité et la performance est laissé à la responsabilité de l'utilisateur.
) tandis que le nombre de règles ainsi que le nombre de SEF doivent être raisonnablement petits. Le compromis entre la complexité et la performance est laissé à la responsabilité de l'utilisateur.
Remarque : Cette option ne génère pas directement de SIF.
Cette option, disponible dans le sous-menu Induction de règles-Option HFP SIF, permet de créer un fichier de configuration du SIF correspondant à une combinaison donnée. Le choix de la combinaison est fait par l'utilisateur, après examen des résultats de l'étape de sélection.
Il faut préciser le fichier de sommets à utiliser, et le nombre de SEF souhaité pour chacune des entrées et la méthode de génération de règles : Wang et Mendel ou bien Fpa (et, dans ce cas, les paramètres qui lui sont nécessaires). Le SIF ainsi créé pourra ensuite être utilisé tel quel, ou bien en entrée du menu simplification.